Turbopuffer
Turbopuffer · Ranked #7 of 7 in Vector Database APIs
Object-storage-first serverless search powering Cursor and Notion, extremely cheap at scale but no free tier.
Cheap serverless search on object storage
Overview
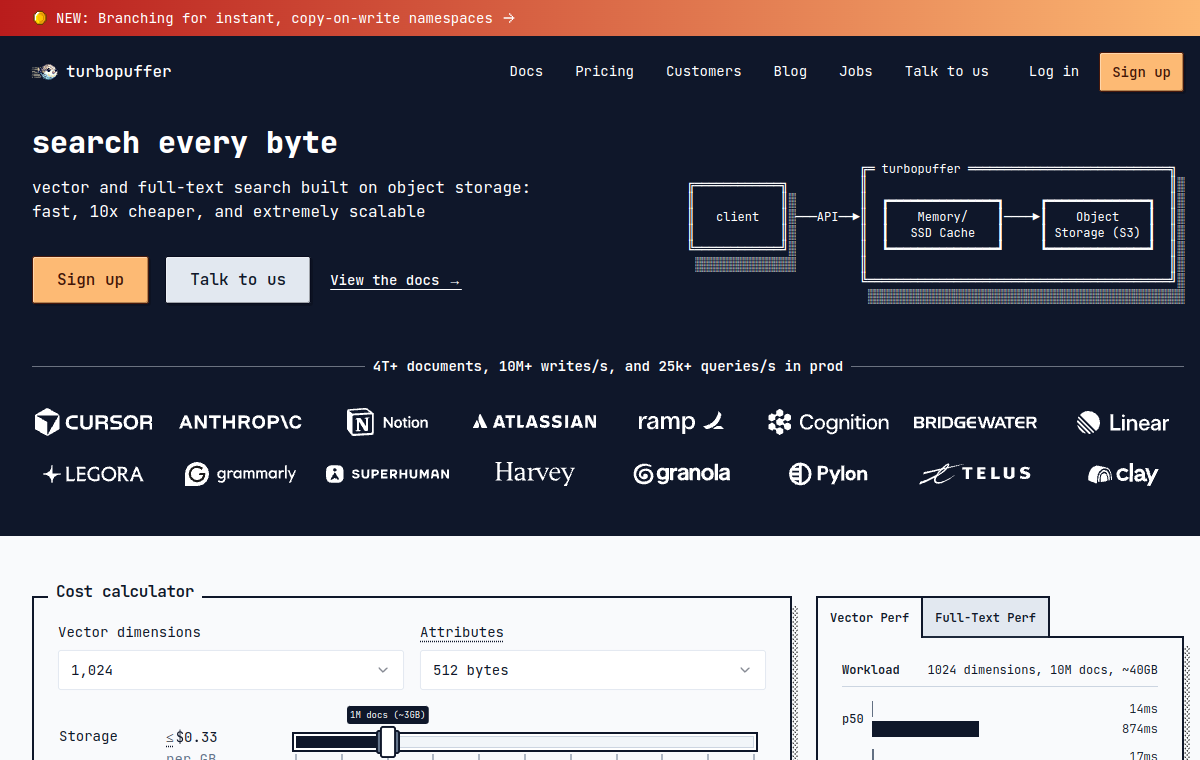
Turbopuffer is a serverless vector and full-text search engine built on object storage (S3/GCS), founded by ex-Shopify engineer Simon Eskildsen. Its core architectural bet is to keep the system of record on cheap object storage (~$20/TB/month) while promoting hot data to NVMe SSD and RAM caches based on access patterns. This three-tier hierarchy lets it claim in-memory-class latency on warm queries (~10ms p90 for vector, ~18ms p90 for BM25 on 1M docs) at roughly 10x lower cost than RAM-resident incumbents like Pinecone. The tradeoff is high cold-query latency (~444ms p90) on first access and relatively high write latency (~248ms p90 for 512KB upserts), since durability is anchored to object storage. It is production-proven at notable scale, powering Cursor, Notion, Linear, Ramp, and others, and the company reports handling 4T+ documents, 10M+ writes/s, and 25k+ queries/s across its fleet.
The ideal user is a team running large-scale RAG, semantic search, or hybrid (vector + BM25 + filter) retrieval where storage volume dominates cost and where occasional cold-start latency on rarely-touched namespaces is acceptable. Multi-tenancy is a first-class concern: namespaces are cheap and isolate per-tenant data, making it a strong fit for AI products that shard search by customer. It is a poor fit for ultra-low-latency, always-hot workloads that need single-digit-ms tail latency on every request regardless of access pattern, or for teams wanting a generous free tier, there is none, and the floor is a $64/month minimum (Launch tier minimum was reduced to $16/month in a later update). Critics (notably Zilliz) argue the object-storage tradeoff hides latency and operational consequences that aren't captured by storage-cost-per-GB alone.
The community sentiment skews positive on operational simplicity, recall auto-tuning, and the engineer-grade product, with the common heuristic being "use pgvector until it breaks, then go to Turbopuffer." The main reservations are pricing for cost-sensitive users versus pgvector, the absence of a free tier, and the inherent cold-query penalty. The product remained invite/waitlist-gated for much of its early life before broader GA, which slowed evaluation for some teams.
How this score is derived
The APIbenchmarks Index is a weighted sum of four dimensions, each scored on an absolute 0–100 reference scale. See the methodology for every mapping.
| Dimension | Score | Weight | Contribution |
|---|---|---|---|
| Documentation & DXDocs are clean and engineer-oriented with quickstart, guarantees, and a transparent published benchmark/pricing-log, though some deep pages (e.g. /docs/benchmark) move or 404 and per-unit pricing is somewhat scattered. | 74 | 30% | 22.2 |
| ReliabilityProduction-proven at 4T+ documents and 10M+ writes/s for customers like Cursor and Notion, with a 99.95% uptime SLA, but only on the Enterprise tier, lower tiers carry no contractual SLA. | 76 | 25% | 19.0 |
| Ecosystem & SDKsOfficial Stainless-generated SDKs for Python, TypeScript, Go, Java and Ruby plus a clean HTTP API give broad language coverage, though it lacks the large third-party integration/connector ecosystem of older incumbents. | 58 | 25% | 14.5 |
| AccessibilitySelf-serve signup with usage-based pricing makes it approachable, but no free tier and a $64/month historical minimum (later $16 Launch floor) raise the bar versus open-source pgvector. | 60 | 20% | 12.0 |
| APIbenchmarks Index (ABI) | 67.7 | ||
Table 1. Derivation of the ABI for Turbopuffer. Contribution = score × weight; the index is their sum.
At a glance
- Vendor
- Turbopuffer
- Pricing model
- Per GB queried/written + storage
- Free tier
- No
- Official SDKs
- 6 languages
Pricing
| Launch | $16/mo minimum | Self-serve usage-based plan with all core database features included; entry tier (previously a $64/month minimum). |
| Scale | $256/mo minimum | Adds HIPAA BAA, SSO, audit logs, and priority support on top of usage-based billing. |
| Enterprise | $4,096+/mo (≈35% usage premium) | Single-tenancy, BYOC, CMEK, private networking, 24/7 support and a 99.95% uptime SLA. |
Key features
- •Serverless vector search on object storage (S3/GCS) with NVMe + RAM caching tiers
- •Full-text BM25 search with text boosting
- •Hybrid dense + sparse vector search with >90% recall
- •Attribute filtering against an inverted index
- •Regex search via trigram indexes
- •First-class namespaces for multi-tenant isolation
- •Branching via copy-on-write clones
- •Configurable read-after-write consistency guarantees
- •Automatic recall tuning based on data
Official SDKs
Strengths & trade-offs
- +Object-storage-first architecture cuts storage cost to ~$20-70/TB/month versus ~$1,600/TB/month for RAM-resident incumbents
- +Warm query latency competitive with in-memory engines (~10ms p90 vector, ~18ms p90 BM25 on 1M docs)
- +Native hybrid search: dense + sparse vectors, BM25 full-text, attribute filtering, and regex via trigram indexes
- +Cheap, first-class namespaces make per-tenant multi-tenancy economical at scale
- +Automatic recall tuning and >90% recall without manual index parameter wrangling
- +Proven in production at very large scale (Cursor, Notion, Linear, Ramp), 4T+ docs, 25k+ queries/s
- –High cold-query latency (~444ms p90) when a namespace isn't cached, bad for always-must-be-fast workloads
- –Relatively high write latency (~248ms p90 for 512KB upserts) due to object-storage durability path
- –No free tier and a monthly spend minimum, making pgvector cheaper for small/early projects
- –99.95% uptime SLA is gated to the expensive Enterprise tier only
- –Smaller third-party integration ecosystem than older incumbents like Pinecone or Elastic
- –Critics argue the storage-cost framing understates real latency/operational tradeoffs of serverless object-storage search
What developers say
Developers praise its operational simplicity, recall auto-tuning, and engineer-grade design; the main reservations are the lack of a free tier, pricing versus pgvector, and the cold-query latency tradeoff.
“In terms of operational simplicity, turbopuffer just killing it [compared to Qdrant and Zilliz Cloud].”
Key figures
| Warm vector query latency (1M 768-dim vectors) | ~10ms p90 | Turbopuffer official benchmark/blog ↗ |
| Cold vector query latency (1M 768-dim vectors) | ~444ms p90 | Turbopuffer official benchmark/blog ↗ |
| Warm BM25 full-text query latency (1M docs) | ~18ms p90 | Turbopuffer official benchmark/blog ↗ |
| Write latency (512KB upserts) | ~248ms p90 | Turbopuffer docs ↗ |
| Storage cost (S3 + SSD cache) | $70/TB/month (vs ~$1,600/TB/month incumbents) | Turbopuffer official blog ↗ |
| Enterprise uptime SLA | 99.95% | Turbopuffer pricing page ↗ |
| Production scale | 4T+ documents, 10M+ writes/s, 25k+ queries/s | Turbopuffer docs ↗ |
Compare Turbopuffer head to head
Sources
- https://turbopuffer.com/pricing
- https://turbopuffer.com/blog/turbopuffer
- https://turbopuffer.com/docs
- https://turbopuffer.com/docs/pricing-log
- https://github.com/turbopuffer/turbopuffer-typescript
- https://github.com/turbopuffer/turbopuffer-go
- https://news.ycombinator.com/item?id=40916786
- https://zilliz.com/blog/the-cost-of-consequence-what-no-one-tells-you-about-serverless-vector-databases
- https://www.modern-datatools.com/tools/turbopuffer
Figures last verified 2026-06-27. Spotted an error? corrections@apibenchmarks.com